

In this week's roundup, I'm gathering some of the most important and interesting data, technology & digital law news from the past week.
Legal and regulatory developments
A) New laws, regulatory proposals, enforcement actions
The EU General Court dismissed the action for annulment of the new framework for the transfer of personal data between the European Union and the United States (the EU-US Data Privacy Framework). This confirms that, as of now, the US ensures an adequate level of protection for personal data transferred from the European Union to organisations in the US. (Case T-553/23; the full text of the judgment is available here.)
Background: Philippe Latombe, a French citizen (and a member of the EU Parliament) and user of various IT platforms that collect his personal data and transfer them to the United States, asked the General Court to annul the adequacy decision adopted by the Commission regarding the US on 10 July 2023. According to Mr Latombe, the US Data Protection Review Court (DPRC) is neither impartial nor independent, but dependent on the executive. Moreover, he submitted that the practice of the intelligence agencies of that country of collecting in bulk personal data in transit from the EU, without the prior authorisation of a court or an independent administrative authority, is not circumscribed in a sufficiently clear and precise manner and is, therefore, illegal. The Court rejected both arguments. The Court found that DPRC operates with sufficient guarantees of independence and the Court also underlined that EU law does not require prior authorisation for bulk data collection. According to the judgment, it cannot be considered that the bulk collection of personal data by US intelligence agencies falls short of the requirements arising from Schrems II or that US law fails to ensure a level of legal protection that is essentially equivalent to that guaranteed by EU law. The General Court also observed that the EU Commission is required to monitor continuously the application of the legal framework on which that decision is based. Thus, if the legal framework in the US changes, the Commission may decide, if necessary, to suspend, amend or repeal the adequacy decision or to limit its scope.
Why does this matter? This judgment provides, at least for now, legal certainty for businesses relying on the EU-US Data Privacy Framework for their data transfers to the US. The EU-US Data Privacy Framework remains valid, allowing continued data flows to the US without additional transfer mechanisms like Standard Contractual Clauses (SCC) or Binding Corporate Rules (BCR).
What´s next: The case may be appealed to the Court of Justice, and further challenges against the EU-US Data Privacy Framework can be expected. (NOYB and Max Schrems already criticised the decision and they might challange the Data Privacy Framework.)
Deeper insight: Beyond the press release, very important methodological takeaways are mentioned by Professor Theodore Christakis regarding the judgment (e.g. about “essentially equivalence”, reliance on ECtHR jurisprudence and temporal frame of the assessment).
Another remarkable judgment of the European Court of Justice was published in the EDPS v SRB case (concept of personal data). The ECJ has confirmed that the interpretation of the General Court was correct in so far as it held that pseudonymised data must not be regarded as constituting, in all cases and for every person, personal data. (The full text of the judgment is available here.)
Why does this matter? Based on the judgment, “pseudonymised data must not be regarded as constituting, in all cases and for every person, personal data for the purposes of the application of Regulation 2018/1725, in so far as pseudonymisation may, depending on the circumstances of the case, effectively prevent persons other than the controller from identifying the data subject in such a way that, for them, the data subject is not or is no longer identifiable.” It is also stated by the Court that “[…] the identifiable nature of the data subject must be assessed at the time of collection of the data and from the point of view of the controller.”
As the Hamburg DPA emphasizes, “this question arises repeatedly in the context of medical or statistical research data, but can also be very relevant in the training of AI models or the application of AI systems, as anonymised data sets are training and output data that comply with the GDPR.”
Deeper insight: For further analysis, please see Oliver Schmidt-Prietz´s summary of the main points and the possible impacts of the judgment. You can read the Hamburg DPA´s first reaction to the judgment here.
The French Data Protection Authority (CNIL) imposed a fine of EUR 325 million on Google (EUR 200 million against Google LLC and EUR 125 million against Google Ireland Limited) for displaying advertisements between Gmail users´ emails without their consent and for placing cookies when creating Google accounts, without valid consent of French users.
Why does this matter? In addition to the above fine, the CNIL also issued “an order requiring the companies to implement, within six months, measures to cease displaying advertisements between emails in the Gmail service users' mailboxes without prior consent and to ensure valid consent from users for the placement of advertising cookies when creating a Google account. Failing this, the companies will each have to pay a penalty of €100,000 per day of delay.”
The CNIL also imposed a fine of EUR 150 million on Infinite Styles Services Co. Limited, the Irish subsidiary of the SHEIN group, for failing to comply with the rules applicable to cookies placed on the devices of users visiting the “shein.com” website.
Why does this matter? “The restricted committee sanctioned several of the company's practices that were contrary to the French Data Protection Act (Article 82): (i) failure to obtain users consent before placing cookies, (ii) two incomplete information banners (no information about the purpose of cookies), (iii) insufficient second-level information (no information on the identity of third parties likely to place cookies), (iv) inadequate mechanisms for refusing and withdrawing consent (when users rejeted the cookies or decided to withdraw their consent, new cookies were still placed and others, already present, continued to be read).”
A US federal judge has ordered that “Google will not have to sell its Chrome web browser but must share information with competitors”.
Why does this matter? “The US Department of Justice had demanded that Google sell Chrome - Tuesday's decision means the tech giant can keep it but it will be barred from having exclusive contracts and must share search data with rivals. […] Google will also not have to sell off its Android operating system, which powers most of the world's smartphones. […] Google will not be allowed to enter into any exclusive contracts for Google Search, Chrome, Google Assistant or the Gemini app.”
B) Guidelines, opinions & more
The State Commissioner for Data Protection and Freedom of Information Baden-Württemberg (Baden-Württemberg DPA) has updated its online tool, the Navigator AI & Data Protection Guides (ONKIDA).
Why does this matter? “The tool is continuously being developed and serves as a working aid for all those who want to integrate AI into work processes in authorities and companies. The clearly structured overview identifies key data protection aspects in the use of AI and provides the associated legal information.”
The European Commission launched a stakeholder consultation to support the development of guidelines and a Code of Practice on the transparency requirements for certain AI systems under Article 50 of the AI Act. (The consultation will be open for 4 weeks starting on 4 September until 2 October 2025.)
Why does this matter? “The purpose of the present targeted stakeholder consultation is to collect input from a wide range of stakeholders to inform the Commission guidelines and a Code of Practice on the detection and labelling of artificially generated or manipulated content. These topics will relate to specific practical examples on how the transparency requirements can be implemented, including issues that may require clarification whether they fall under the scope of Article 50 AI Act and under what conditions, information on state-of-the-art transparency and disclosure practices or other conceptual clarifications.”
UK´s Information Commissioner´s Office (ICO) published the updated version of its guidance on encryption.
Why does this matter? “This guidance will help you to understand: (i) the importance of encryption as an appropriate technical measure to protect the personal information you hold; and (ii) how to implement it.”
C) Publications, reports
The US National Institute of Standards and Technology (NIST) revised its Security and Privacy Control Catalog to improve software update and patch releases. (Summary of Changes: NIST SP 800-53 Release 5.2.0)
Why does this matter? “The changes […] address multiple aspects of the software development and deployment process, including addressing software and system resiliency by design, developer testing, deployment and management of updates, and software integrity and validation. […] The update also revises the technical content of some existing controls and provides additional examples of how to implement them.”
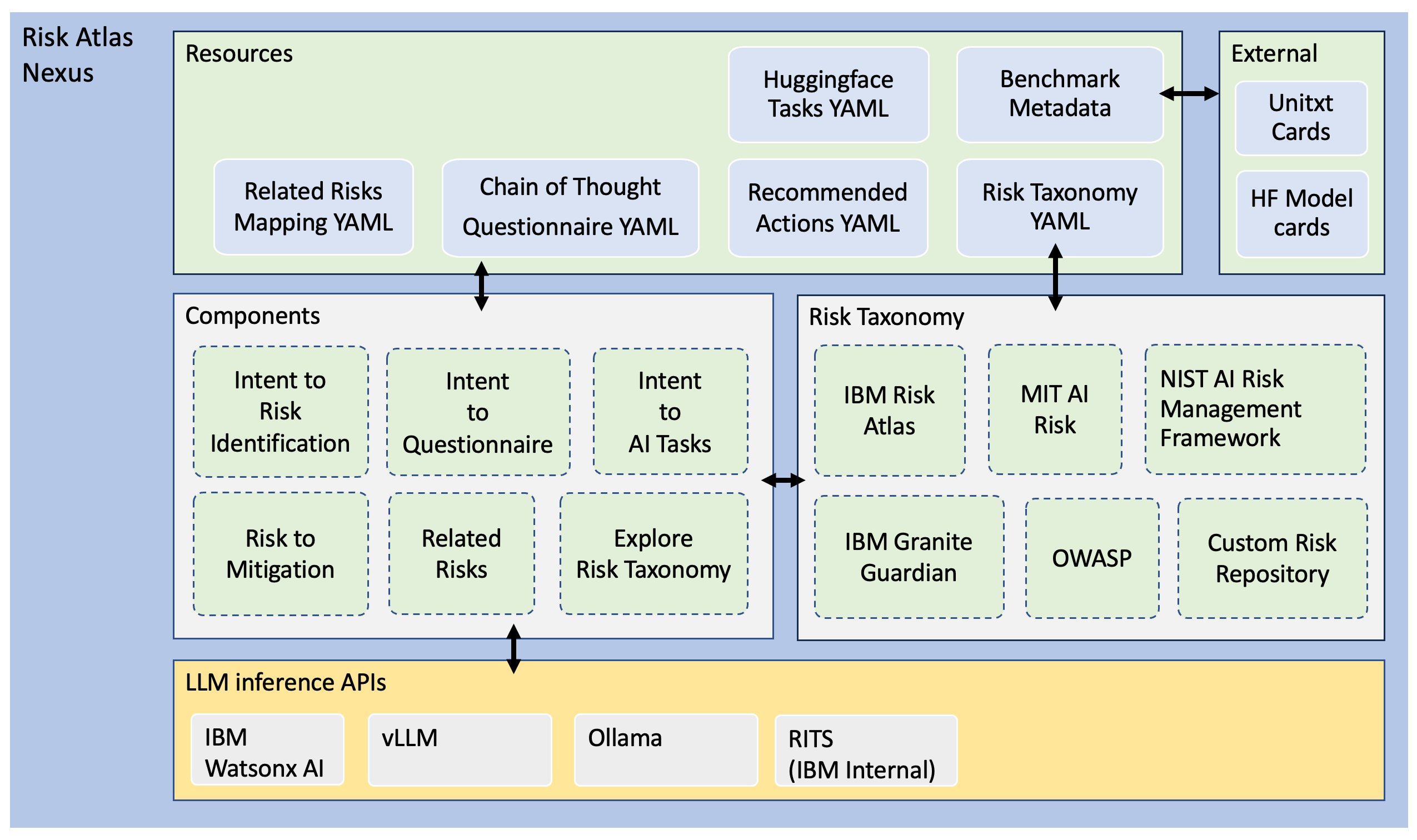
IBM released AI Risk Atlas.
Why does this matter? “Risk Atlas Nexus aims to provide tooling to help bring together resources related to governance of foundation models. We support a community-driven approach to curating and cataloguing resources such as datasets, benchmarks and mitigations. Our goal is to turn abstract risk definitions into actionable workflows that streamline AI governance processes. By connecting fragmented resources, Risk Atlas Nexus seeks to fill a critical gap in AI governance, enabling stakeholders to build more robust, transparent, and accountable systems. Risk Atlas Nexus builds on the IBM AI Risk Atlas making this educational resource a nexus of governance assets and tooling. An AI System's Knowledge Graph is used to provide a unified structure that links and contextualize the very heterogeneous domain data.”
Architecture of Risk Atlas Nexus:
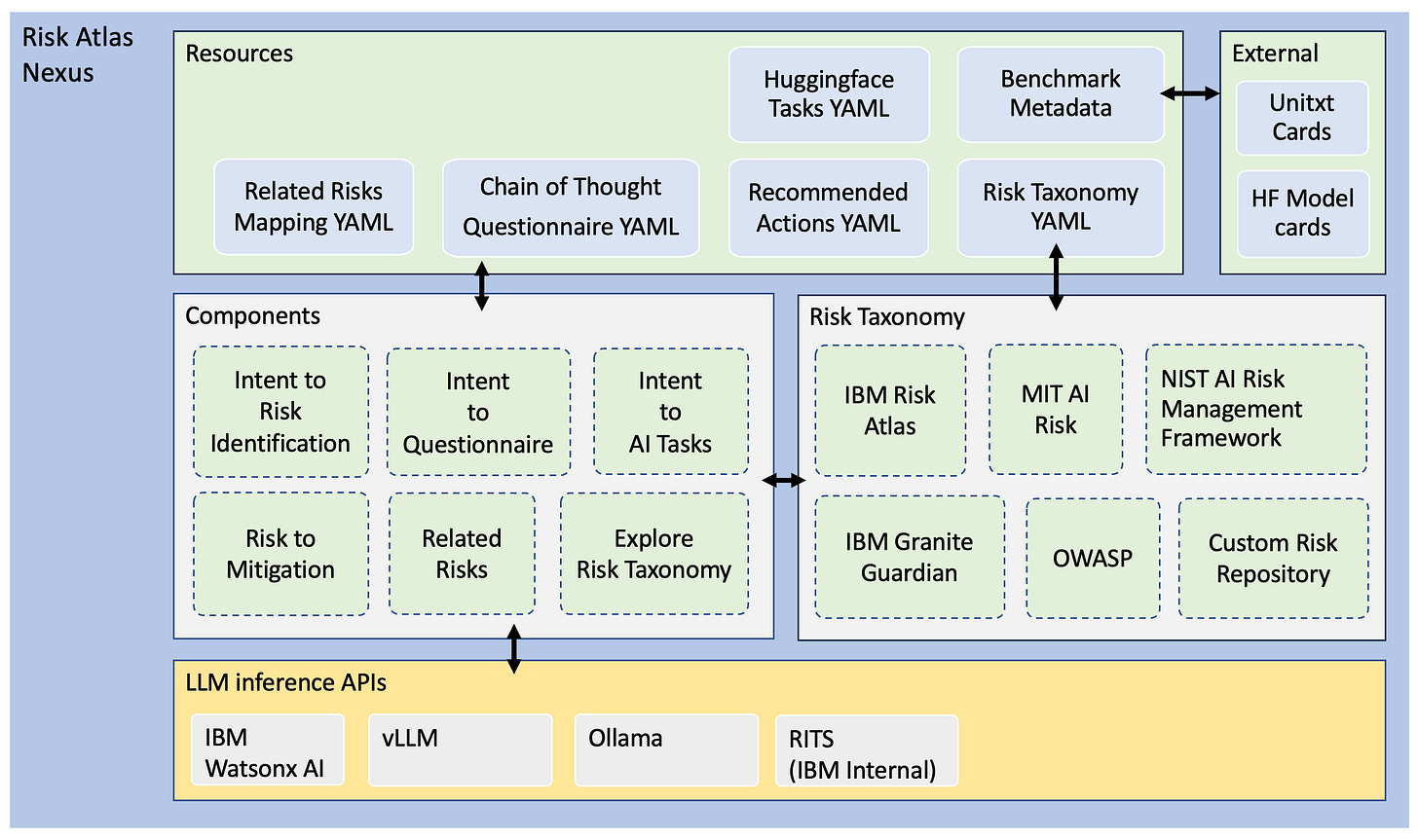
(Source: GitHUB)
UNESCO published a book titled “AI and the future of education: disruptions, dilemmas and directions”.
Why does this matter? “This anthology explores the philosophical, ethical and pedagogical dilemmas posed by disruptive influence of AI in education. Bringing together insights from global thinkers, leaders and changemakers, the collection challenges assumptions, surfaces frictions, provokes contestation, and sparks audacious new visions for equitable human-machine co-creation. Covering themes from dismantling outdated assessment systems to cultivating an ethics of care, the 21 think pieces in this volume take a step towards building a global commons for dialogue and action, a shared space to think together, debate across differences, and reimagine inclusive education in the age of AI.”
Data, Technology & Company news
Google added AI-powered live audio conversations and language learning capabilities to Google Translate. The new features are using the advanced reasoning and multimodal capabilities of Gemini models.
Why does this matter? “[…] we’ve introduced the ability to have a back-and-forth conversation in real time with audio and on-screen translations through the Translate app. Building on our existing live conversation experience, our advanced AI models are now making it even easier to have a live conversation in more than 70 languages — including Arabic, French, Hindi, Korean, Spanish, and Tamil.”
OpenAI introduced gpt-realtime and Realtime API updates for production voice agents.
Why does this matter? “[…] the Realtime API processes and generates audio directly through a single model and API. This reduces latency, preserves nuance in speech, and produces more natural, expressive responses. […] The new speech-to-speech model—gpt-realtime—is our most advanced, production-ready voice model. We trained the model in close collaboration with customers to excel at real-world tasks like customer support, personal assistance, and education—aligning the model to how developers build and deploy voice agents. The model shows improvements across audio quality, intelligence, instruction following, and function calling. […] gpt-realtime shows higher intelligence and can comprehend native audio with greater accuracy. The model can capture non-verbal cues (like laughs), switch languages mid-sentence, and adapt tone (“snappy and professional” vs. “kind and empathetic”). According to internal evaluations, the model also shows more accurate performance in detecting alphanumeric sequences (such as phone numbers, VINs, etc) in other languages, including Spanish, Chinese, Japanese, and French. On the Big Bench Audio eval measuring reasoning capabilities, gpt-realtime scores 82.8% accuracy—beating our previous model from December 2024, which scores 65.6%.”
Anthropic announced to start training its AI models on user data, including new chat transcripts and coding sessions, unless users choose to opt out. It’s also extending its data retention policy to five years for users that don’t choose to opt out.
Why does this matter? Existing users have to accept the updated Consumer Terms and make their opt-out decision until September 28. If a user chooses to accept the new policies now, they will go into effect immediately. These updates will apply only to new or resumed chats and coding sessions. After September 28, users need to make their selection on the model training setting in order to continue using Claude.